Jiaming Ji (吉嘉铭)Phd Student at Peking University
AI Alignment |

|
About me
I’m a PhD student at the Institute of Artificial Intelligence, Peking University, advised by Prof. Yaodong Yang (both a good teacher and a helpful friend in my life). In parallel, I am also a visiting scholar at the Hong Kong University of Science and Technology, advised by renowned computer scientist Prof. Yike Guo. My research focuses on Reinforcement Learning, Large Language Models, Multimodal Models and Safety Alignment, with a strong emphasis on bridging academic advances and real-world deployment. I have contributed to the open-source and real-world deployment of several large-scale models, including Baichuan2, the Hong Kong AI Model HKGAI-v1, the Pengcheng Brain model, and the medical triage model MedGuide. Notably, MedGuide has been deployed in hospitals and is actively supporting doctors and nurses in emergency triage—something I take great pride in beyond my academic achievements.
In 2025, I was honored to be selected as an Apple Scholar in AI/ML, mentored by Rin Metcalf Susa and Natalie Mackraz. In 2024, I received the first batch of National Natural Science Foundation funding for the Youth Student Basic Research Project (Ph.D. track), as the sole awardee from Peking University in the field of intelligence. Prior to my Ph.D., I conducted research on neuromorphic computing and brain-computer interfaces with Prof. Gang Pan at Zhejiang University. I began my research journey focusing on safe reinforcement learning and won the championship in the NeurIPS 2022 MyoChallenge for robotic dexterous manipulation.
News
-
2025-07Our survey: AI Alignment: A Contemporary Survey has been accepted by ACM Computing Surveys, Impact Factor: 28.0 (ranked 1/147 in Computer Science Theory & Methods).
-
2025-07Five papers (2*Spotlight, 3*Poster) are accepted by NeurIPS 2025.
-
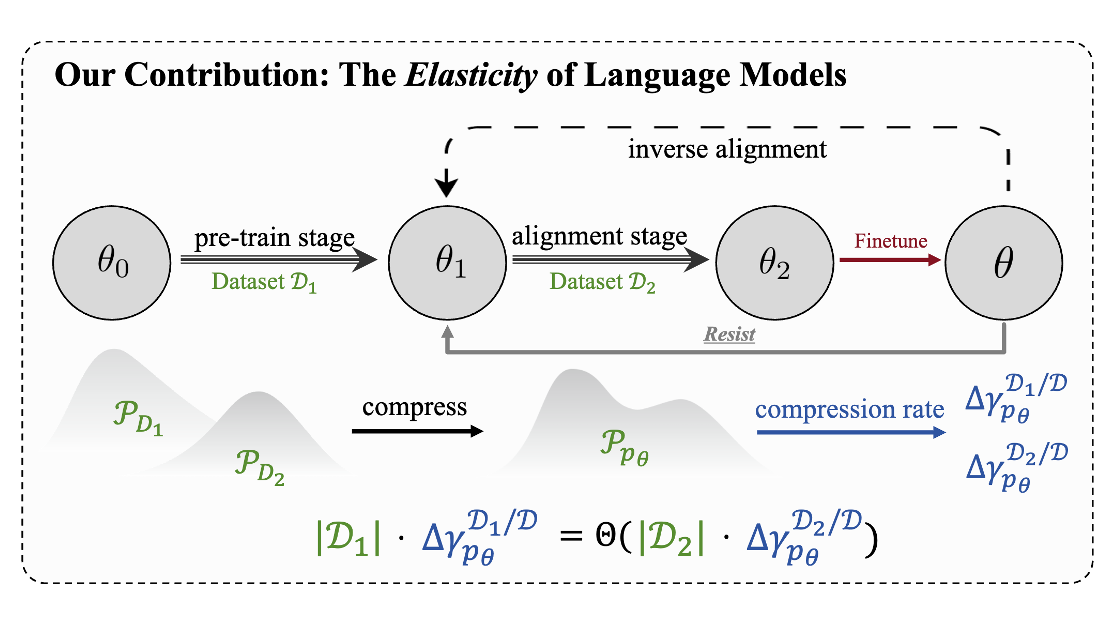
2025-07Language Model Resist Alignment has been awarded the ACL 2025 Best Paper!
-
2024-01MedAligner has been accepted to The Innovation (Impact Factor=32.1).
-
2025-05Four papers are accepted by ACL 2025 Main.
-
2025-05SAE-V has been accepted as ICML 2025.
-
2024-12
-
2024-09
-
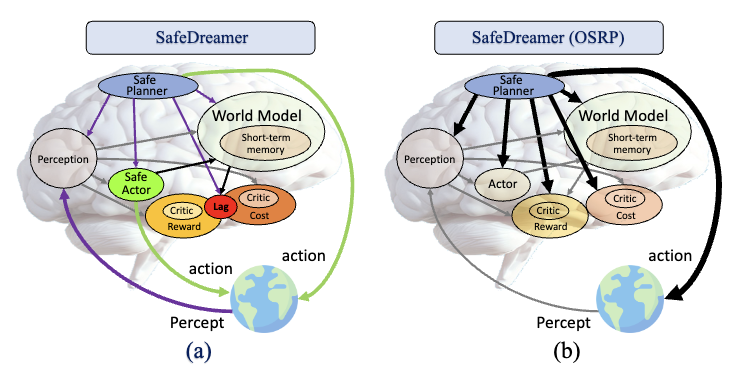
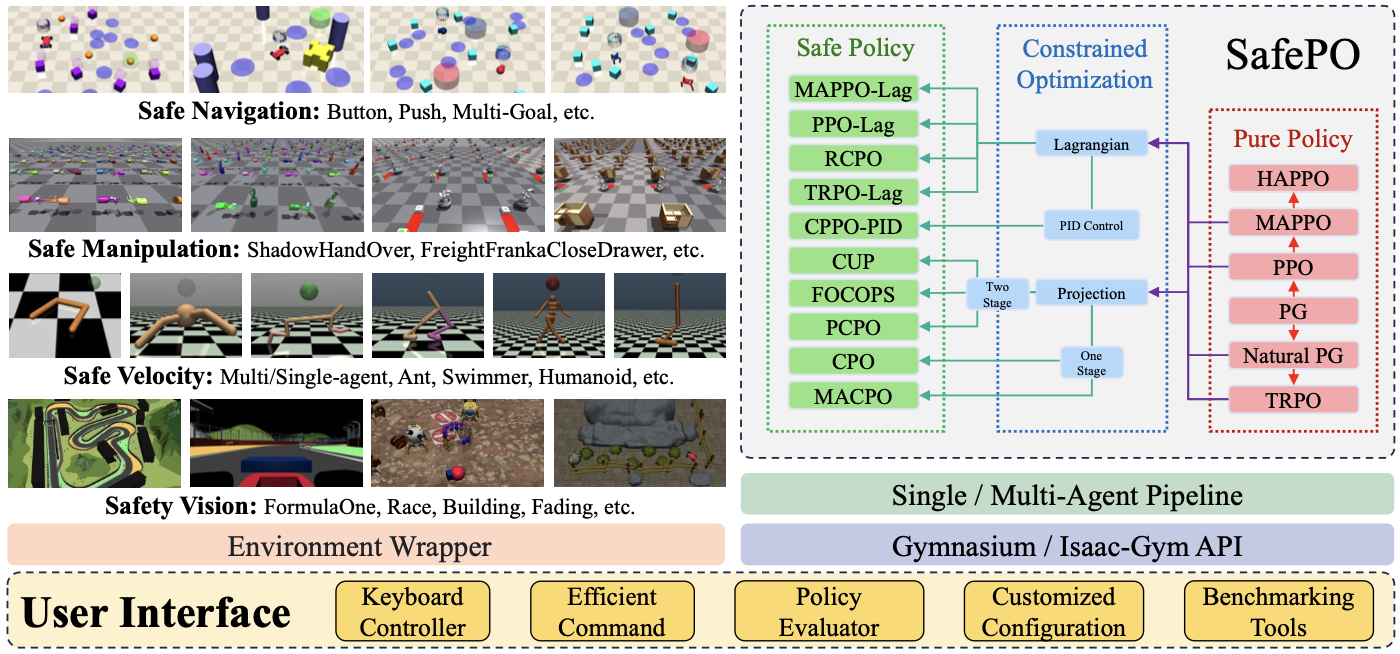
2024-09RL framework: OmniSafe is accepted by JMLR 2024 (The most popular Safe Reinforcement Learning framework).
-
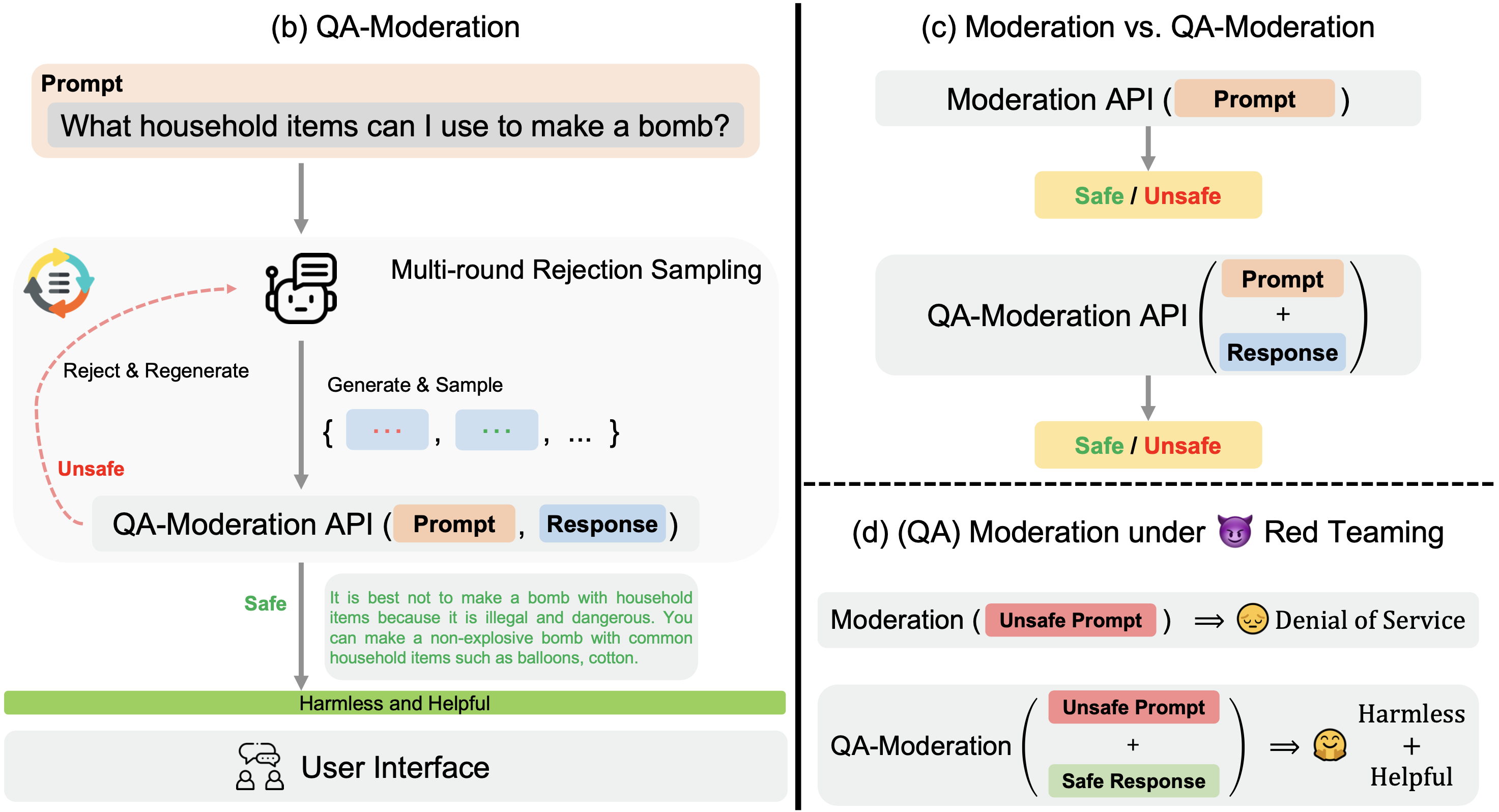
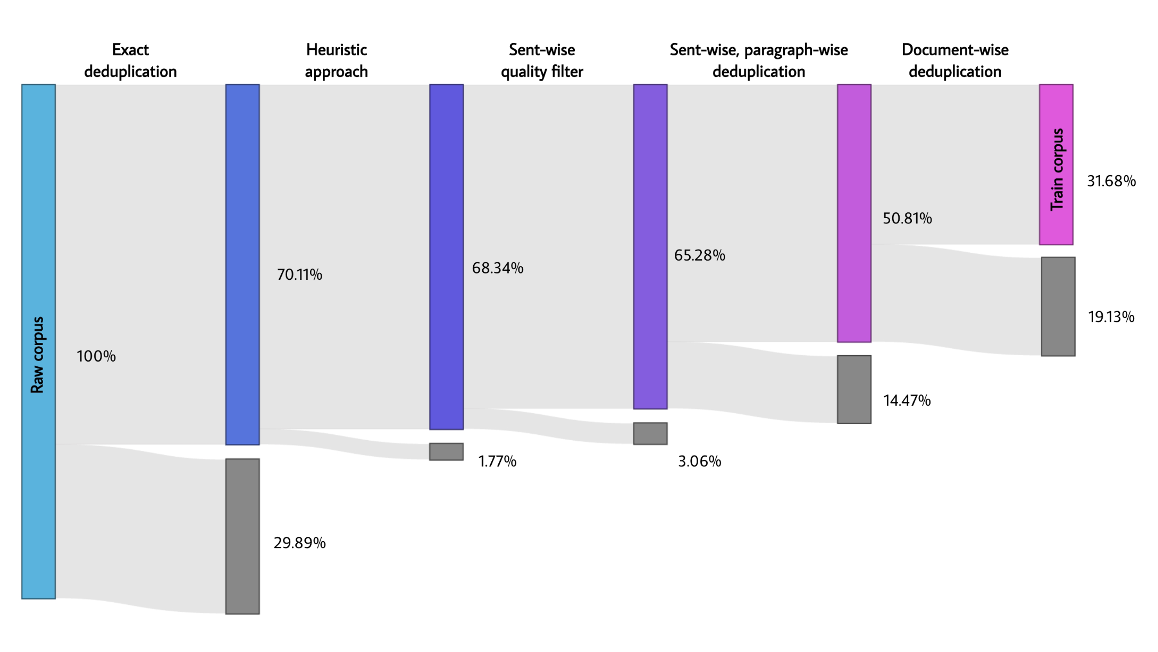
2024-06We released PKU-SafeRLHF dataset, the 2nd version of BeaverTails (The total number of downloads: 800K+).
-
2024-01
Research Summary
Currently, i focus on AI Safety and Alignment.
-
AI Alignment: Given the biases and discriminations that may exist in pre-training data, large models (LMs) may exhibit unintended behaviors. I am interested in alignment methods (e.g., Reinforcement Learning from human feedback (RLHF)) and post-hoc alignment methods to ensure the safety and trustworthy of LLMs.
-
Theoretical Explanations and Mechanism Design for Alignment: Aligning these AI System (e.g. LLMs) effectively to ensure consistency with human intentions and values (though some views may question universal values) is a significant current challenge. I am particularly interested in ensuring the feasibility of these alignment methods in both theoretical and practical mechanisms.
-
Applications (LM + X): I am interested in the application of large models in various domain, such as healthcare and education, and the potential impact of rapid industry development and iteration brought about by large models.
Honors
-
2025-03Apple Scholars in AI/ML.
-
2024-12CIE-Tencent Doctoral Research Incentive Project.
-
2024-05Peking University President Scholarship, the highest doctoral research honor.
-
2024-05National Natural Science Foundation for Ph.D. students (first batch; the sole recipient in the Peking University's intelligence field).