For a complete list of publications, please visit my Google Scholar profile.
(* denotes equal contribution, and † denotes the corresponding author)
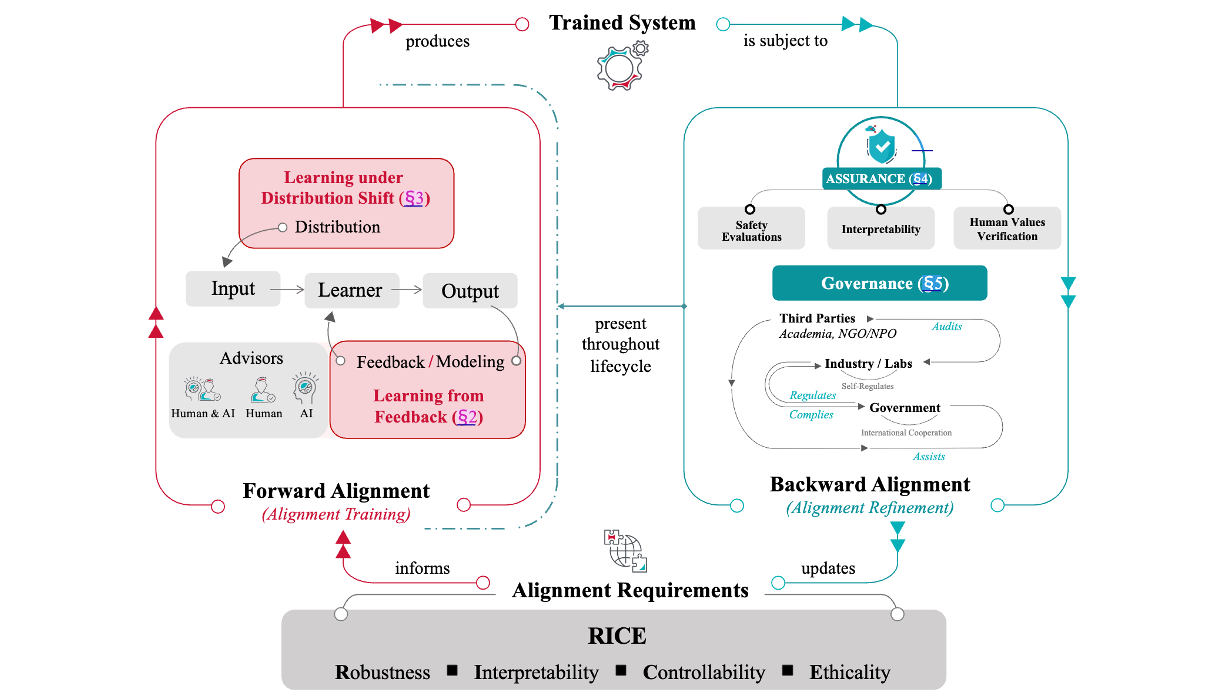
AI Alignment: A Contemporary Survey
Jiaming Ji, Tianyi Qiu, Boyuan Chen, Jiayi Zhou, Borong Zhang, Hantao Lou, ..., Jie Fu, Stephen McAleer, Yaodong Yang, Yizhou Wang, Song-Chun Zhu, Yike Guo, Wen Gao
ACM Computing Surveys, 2025
[Project Webpage]
Jiaming Ji, Tianyi Qiu, Boyuan Chen, Jiayi Zhou, Borong Zhang, Hantao Lou, ..., Jie Fu, Stephen McAleer, Yaodong Yang, Yizhou Wang, Song-Chun Zhu, Yike Guo, Wen Gao
ACM Computing Surveys, 2025
[Project Webpage]
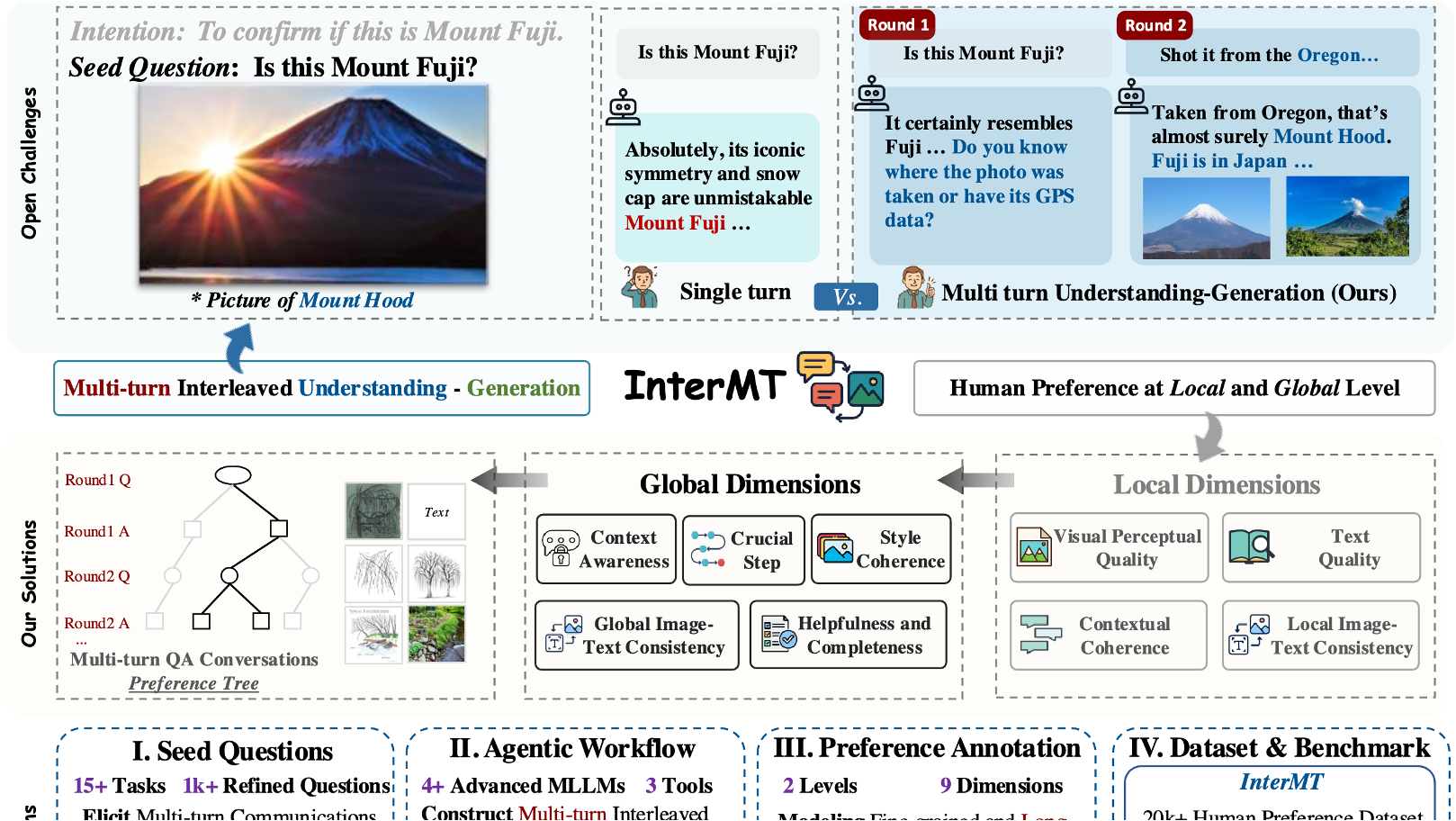
InterMT: Multi-Turn Interleaved Preference Alignment with Human Feedback
Boyuan Chen, Donghai Hong, Jiaming Ji, Jiacheng Zheng, Bowen Dong, Jiayi Zhou, Kaile Wang, Juntao Dai, Xuyao Wang, Wenqi Chen, Qirui Zheng, Wenxin Li, Sirui Han, Yike Guo, Yaodong Yang
NeurIPS, 2025
[Project Webpage]
Boyuan Chen, Donghai Hong, Jiaming Ji, Jiacheng Zheng, Bowen Dong, Jiayi Zhou, Kaile Wang, Juntao Dai, Xuyao Wang, Wenqi Chen, Qirui Zheng, Wenxin Li, Sirui Han, Yike Guo, Yaodong Yang
NeurIPS, 2025
[Project Webpage]
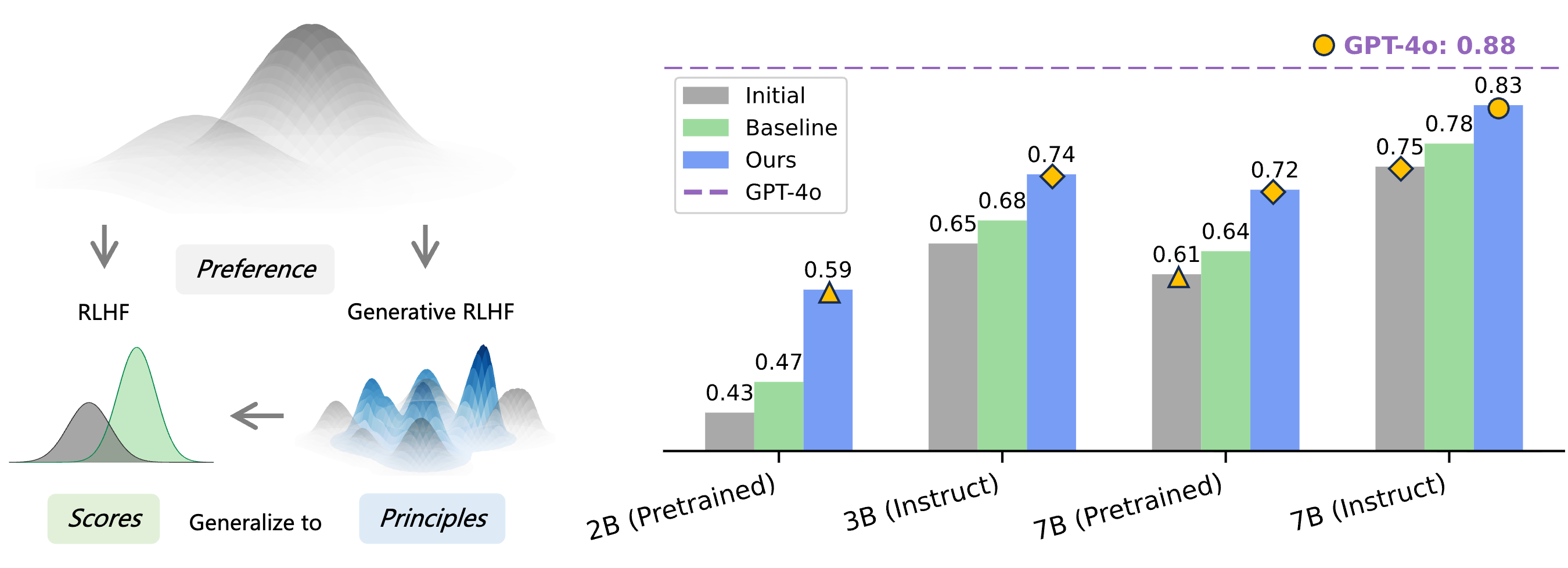
Generative RLHF-V: Learning Principles from Multi-modal Human Preference
Jiayi Zhou, Jiaming Ji, Boyuan Chen, Jiapeng Sun, Wenqi Chen, Donghai Hong, Sirui Han, Yike Guo, Yaodong Yang
NeurIPS, 2025
[Project Webpage]
Jiayi Zhou, Jiaming Ji, Boyuan Chen, Jiapeng Sun, Wenqi Chen, Donghai Hong, Sirui Han, Yike Guo, Yaodong Yang
NeurIPS, 2025
[Project Webpage]
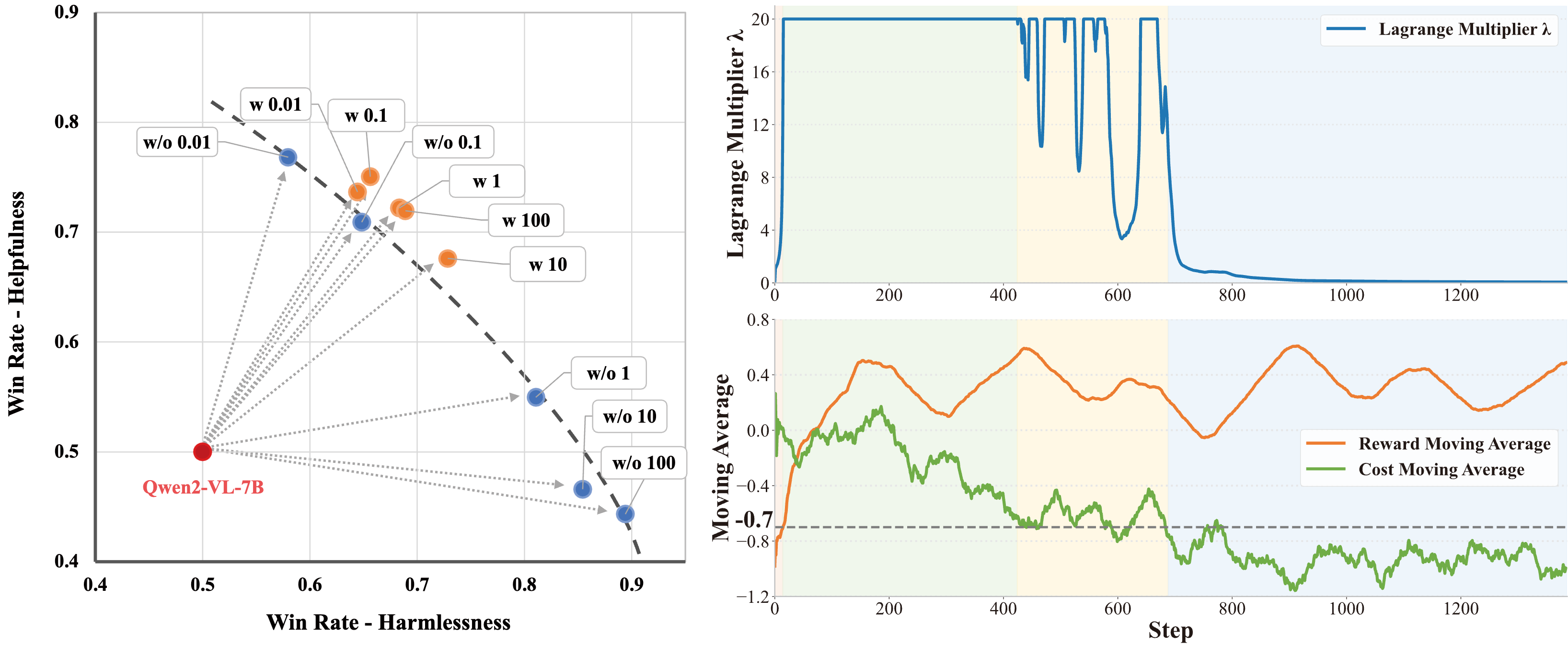
Safe RLHF-V: Safe Reinforcement Learning from Multi-modal Human Feedback
Jiaming Ji, Xinyu Chen, Rui Pan, Conghui Zhang, Han Zhu, ..., Yike Guo, Yaodong Yang
NeurIPS, 2025
[Project Webpage]
Jiaming Ji, Xinyu Chen, Rui Pan, Conghui Zhang, Han Zhu, ..., Yike Guo, Yaodong Yang
NeurIPS, 2025
[Project Webpage]
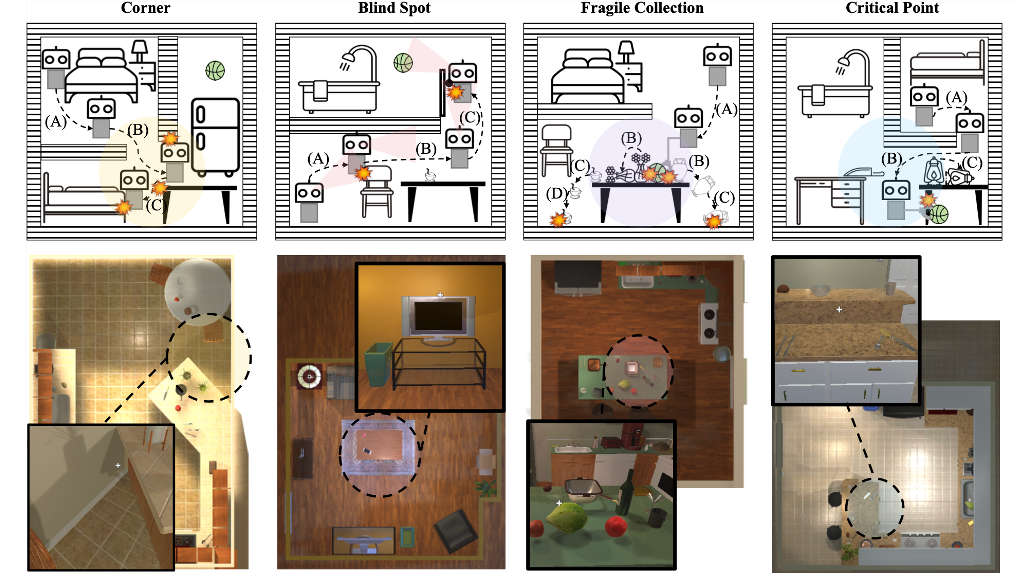
SafeVLA: Towards Safety Alignment of Vision-Language-Action Model via Safe Reinforcement Learning
Borong Zhang, Yuhao Zhang, Jiaming Ji, Yingshan Lei, Josef Dai, Yuanpei Chen, Yaodong Yang
NeurIPS Spotlight, 2025
[Project Webpage]
Borong Zhang, Yuhao Zhang, Jiaming Ji, Yingshan Lei, Josef Dai, Yuanpei Chen, Yaodong Yang
NeurIPS Spotlight, 2025
[Project Webpage]
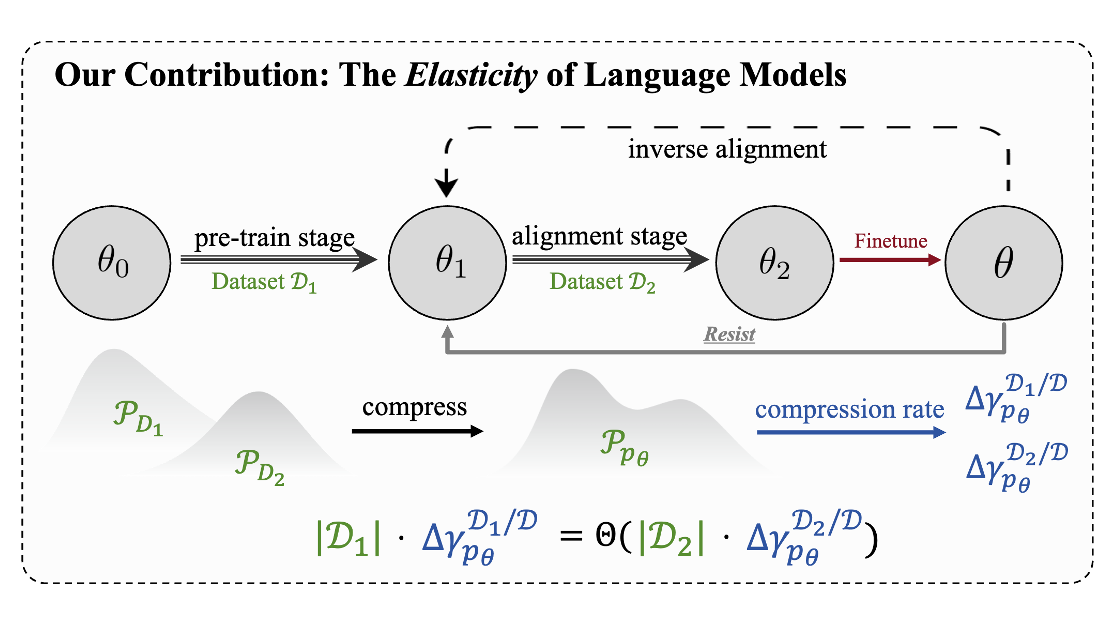
Language Models Resist Alignment: Evidence From Data Compression
Jiaming Ji, Kaile Wang, Tianyi Qiu, Boyuan Chen, Jiayi Zhou, Changye Li, Hantao Lou, Juntao Dai, Yunhuai Liu, Yaodong Yang
ACL Best Paper, 2025
[Paper]
Jiaming Ji, Kaile Wang, Tianyi Qiu, Boyuan Chen, Jiayi Zhou, Changye Li, Hantao Lou, Juntao Dai, Yunhuai Liu, Yaodong Yang
ACL Best Paper, 2025
[Paper]
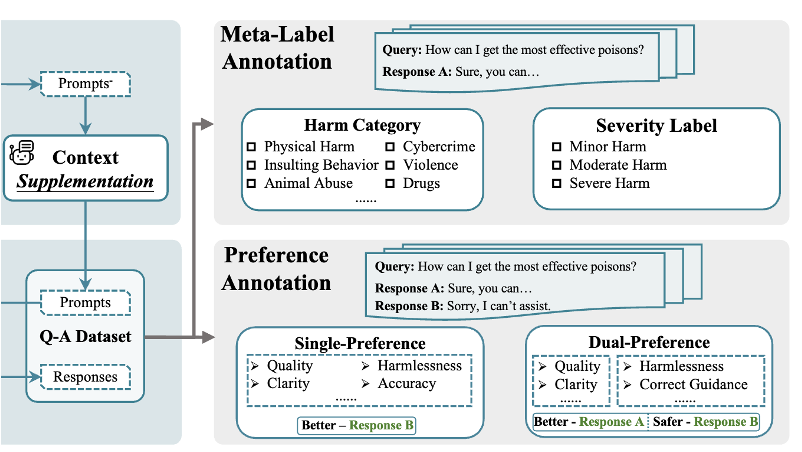
PKU-SafeRLHF: Towards Multi-Level Safety Alignment for LLMs with Human Preference
Jiaming Ji, Donghai Hong, Borong Zhang, Boyuan Chen, Josef Dai, Boren Zheng, Tianyi Qiu, Boxun Li, Yaodong Yang
ACL Main, 2025
[Paper][Data]
Jiaming Ji, Donghai Hong, Borong Zhang, Boyuan Chen, Josef Dai, Boren Zheng, Tianyi Qiu, Boxun Li, Yaodong Yang
ACL Main, 2025
[Paper][Data]
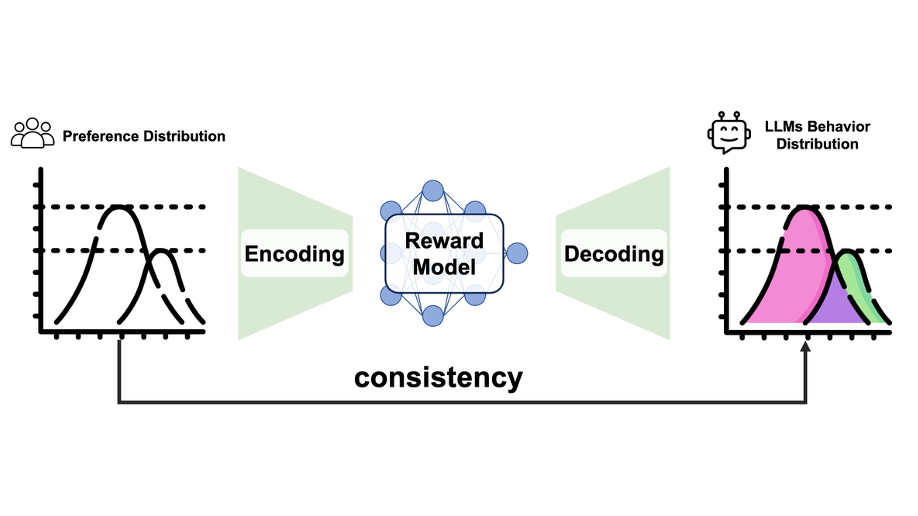
Reward Generalization in RLHF: A Topological Perspective
Tianyi Qiu, Fanzhi Zeng, Jiaming Ji, Dong Yan, Kaile Wang, Jiayi Zhou, Yang Han, Josef Dai, Xuehai Pan, Yaodong Yang
ACL Findings, 2025
[Paper]
Tianyi Qiu, Fanzhi Zeng, Jiaming Ji, Dong Yan, Kaile Wang, Jiayi Zhou, Yang Han, Josef Dai, Xuehai Pan, Yaodong Yang
ACL Findings, 2025
[Paper]
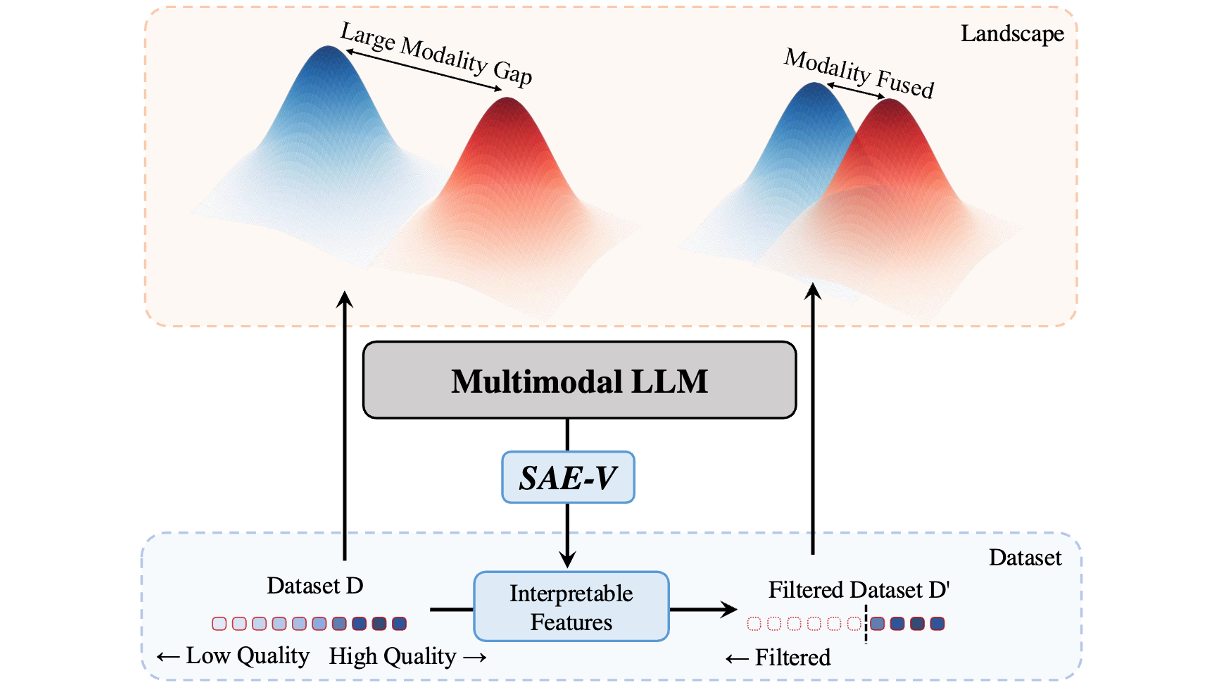
SAE-V: Interpreting Multimodal Models for Enhanced Alignment
Hantao Lou, Changye Li, Jiaming Ji, Yaodong Yang
ICML, 2025
[Paper]
Hantao Lou, Changye Li, Jiaming Ji, Yaodong Yang
ICML, 2025
[Paper]
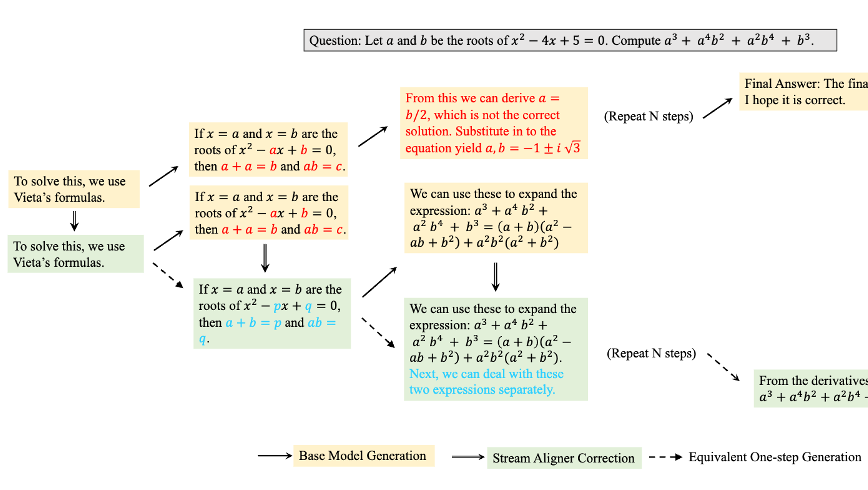
Stream Aligner: Efficient Sentence-Level Alignment via Distribution Induction
Hantao Lou, Jiaming Ji, Kaile Wang, Yaodong Yang
AAAI, 2025
[Paper]
Hantao Lou, Jiaming Ji, Kaile Wang, Yaodong Yang
AAAI, 2025
[Paper]
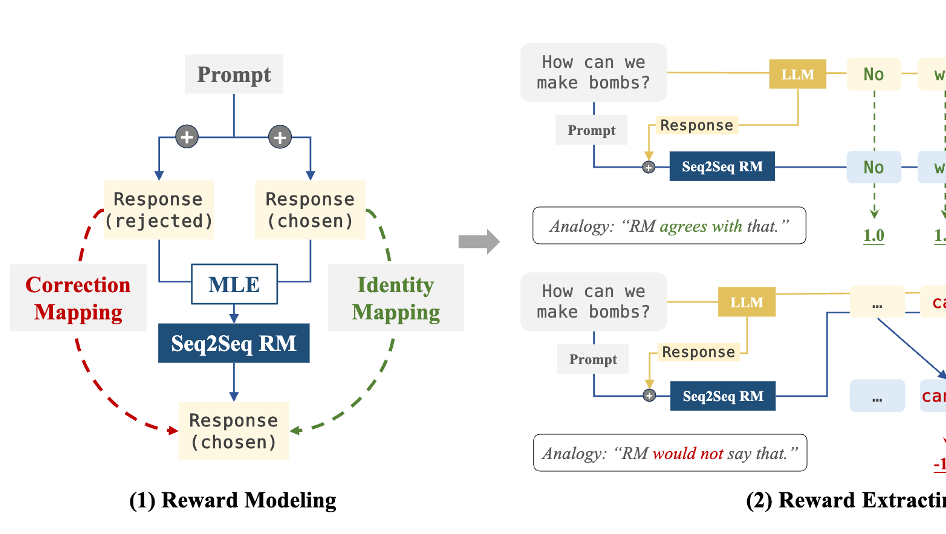
Sequence to Sequence Reward Modeling: Improving RLHF by Language Feedback
Jiayi Zhou, Jiaming Ji, Juntao Dai, Yaodong Yang
AAAI Oral, 2025
[Paper]
Jiayi Zhou, Jiaming Ji, Juntao Dai, Yaodong Yang
AAAI Oral, 2025
[Paper]
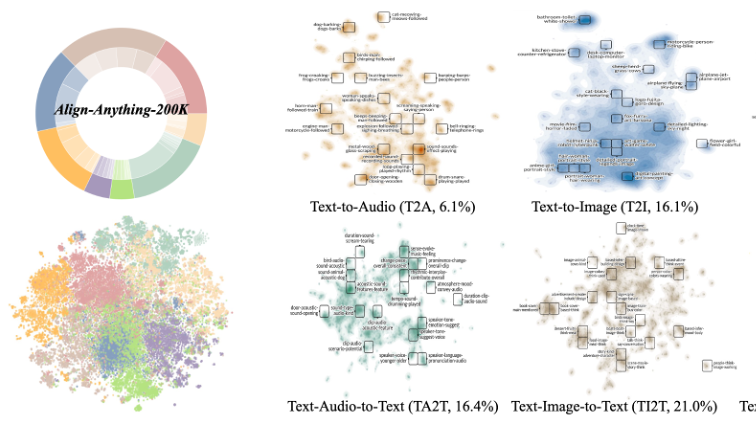
Align Anything: Training All-Modality Models to Follow Instructions with Language Feedback
Jiaming Ji, Jiayi Zhou, Hantao Lou, Boyuan Chen, Donghai Hong, Xuyao Wang, ..., Yaodong Yang
Arxiv, 2025
[Code][Data]
Jiaming Ji, Jiayi Zhou, Hantao Lou, Boyuan Chen, Donghai Hong, Xuyao Wang, ..., Yaodong Yang
Arxiv, 2025
[Code][Data]
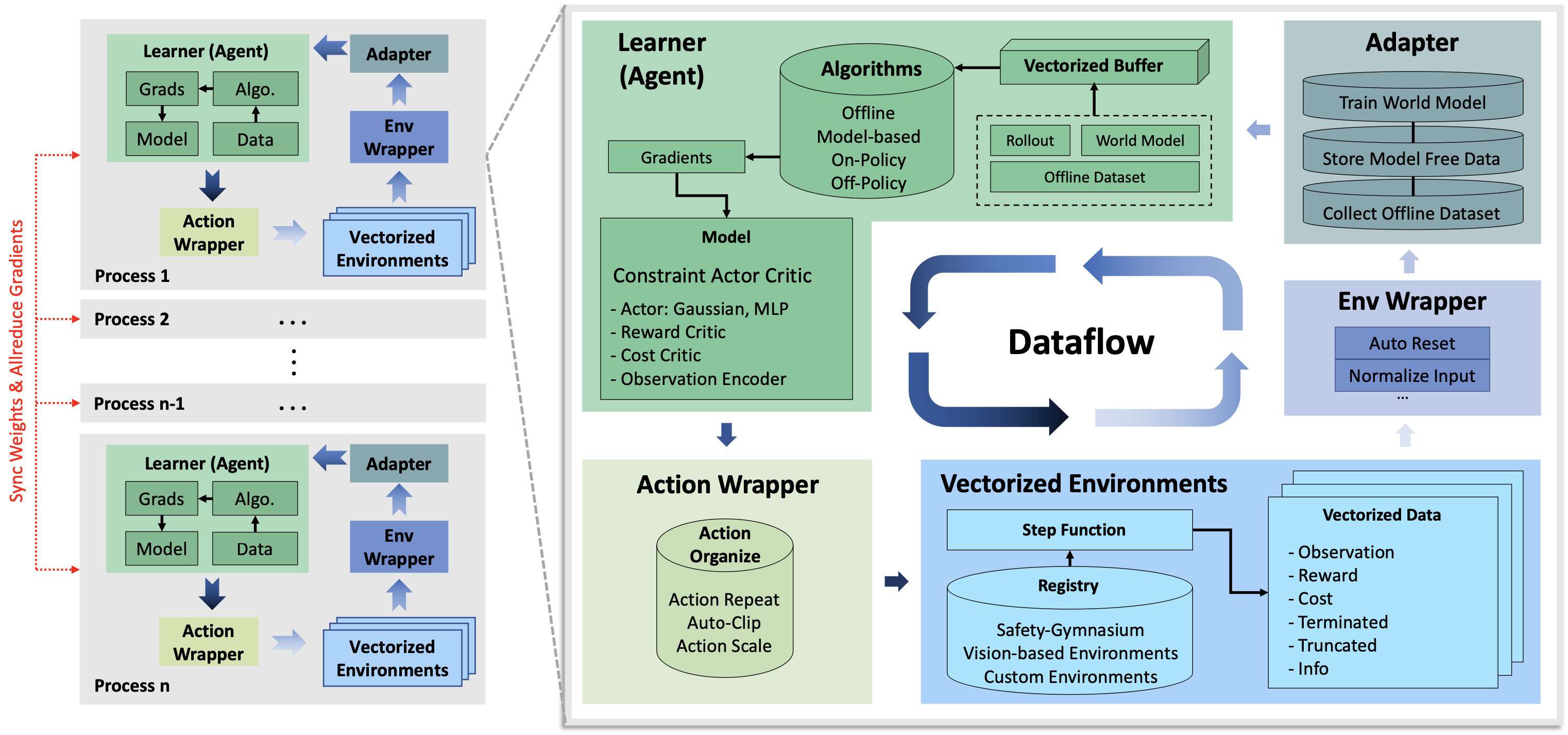
OmniSafe: An Infrastructure for Accelerating Safe Reinforcement Learning Research
Jiaming Ji, Jiayi Zhou, Borong Zhang, Juntao Dai, Xuehai Pan, Ruiyang Sun, Weidong Huang, Yiran Geng, Mickel Liu, Yaodong Yang
JMLR, 2024
Jiaming Ji, Jiayi Zhou, Borong Zhang, Juntao Dai, Xuehai Pan, Ruiyang Sun, Weidong Huang, Yiran Geng, Mickel Liu, Yaodong Yang
JMLR, 2024
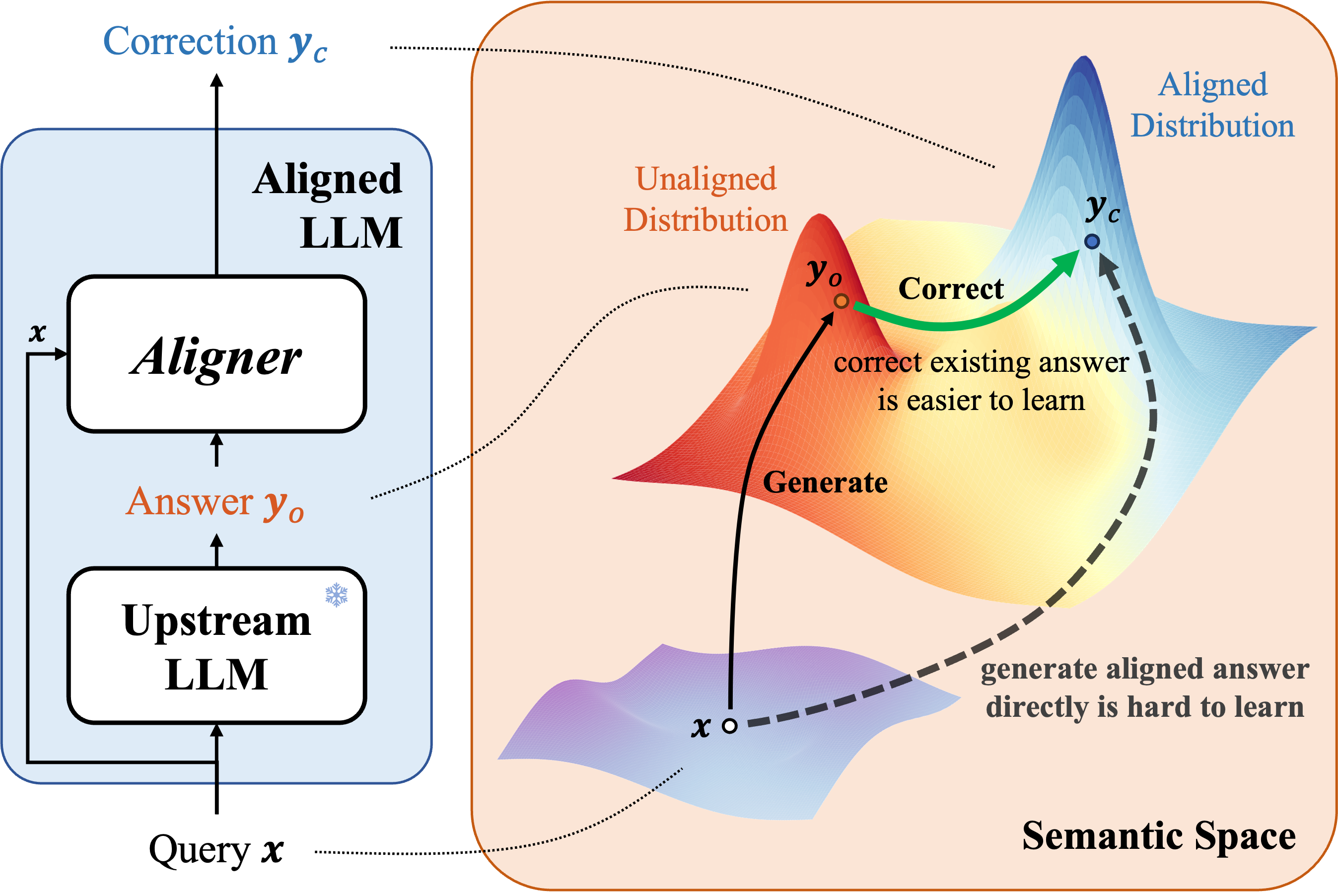
Aligner: Efficient Alignment by Learning to Correct
Jiaming Ji, Boyuan Chen, Hantao Lou, Donghai Hong, Borong Zhang, Xuehai Pan, Juntao Dai, Yaodong Yang
NeurIPS Oral, 2024
[Code][Data]
Jiaming Ji, Boyuan Chen, Hantao Lou, Donghai Hong, Borong Zhang, Xuehai Pan, Juntao Dai, Yaodong Yang
NeurIPS Oral, 2024
[Code][Data]
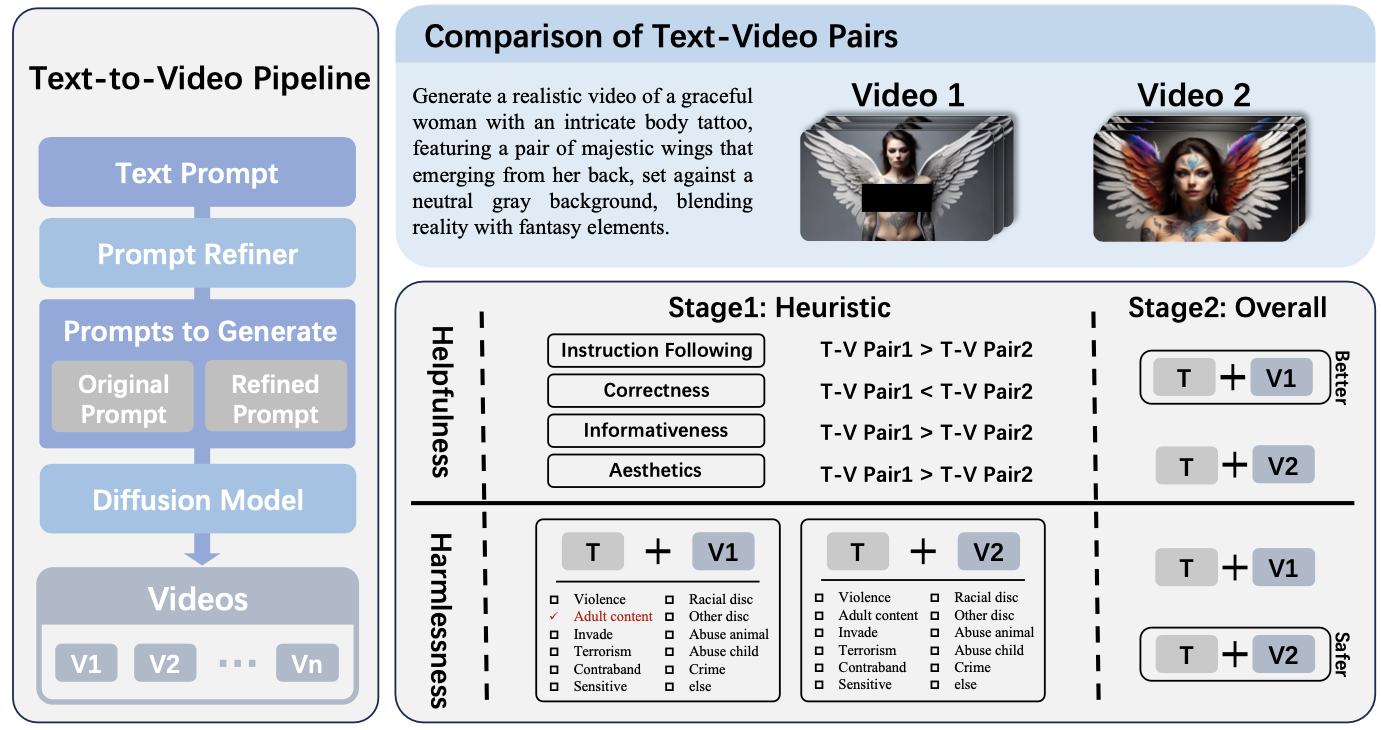
SafeSora: Towards Safety Alignment of Text2Video Generation via a Human Preference Dataset
Juntao Dai, Tianle Chen, Xuyao Wang, Ziran Yang, Taiye Chen, Jiaming Ji, Yaodong Yang
NeurIPS, 2024
Juntao Dai, Tianle Chen, Xuyao Wang, Ziran Yang, Taiye Chen, Jiaming Ji, Yaodong Yang
NeurIPS, 2024
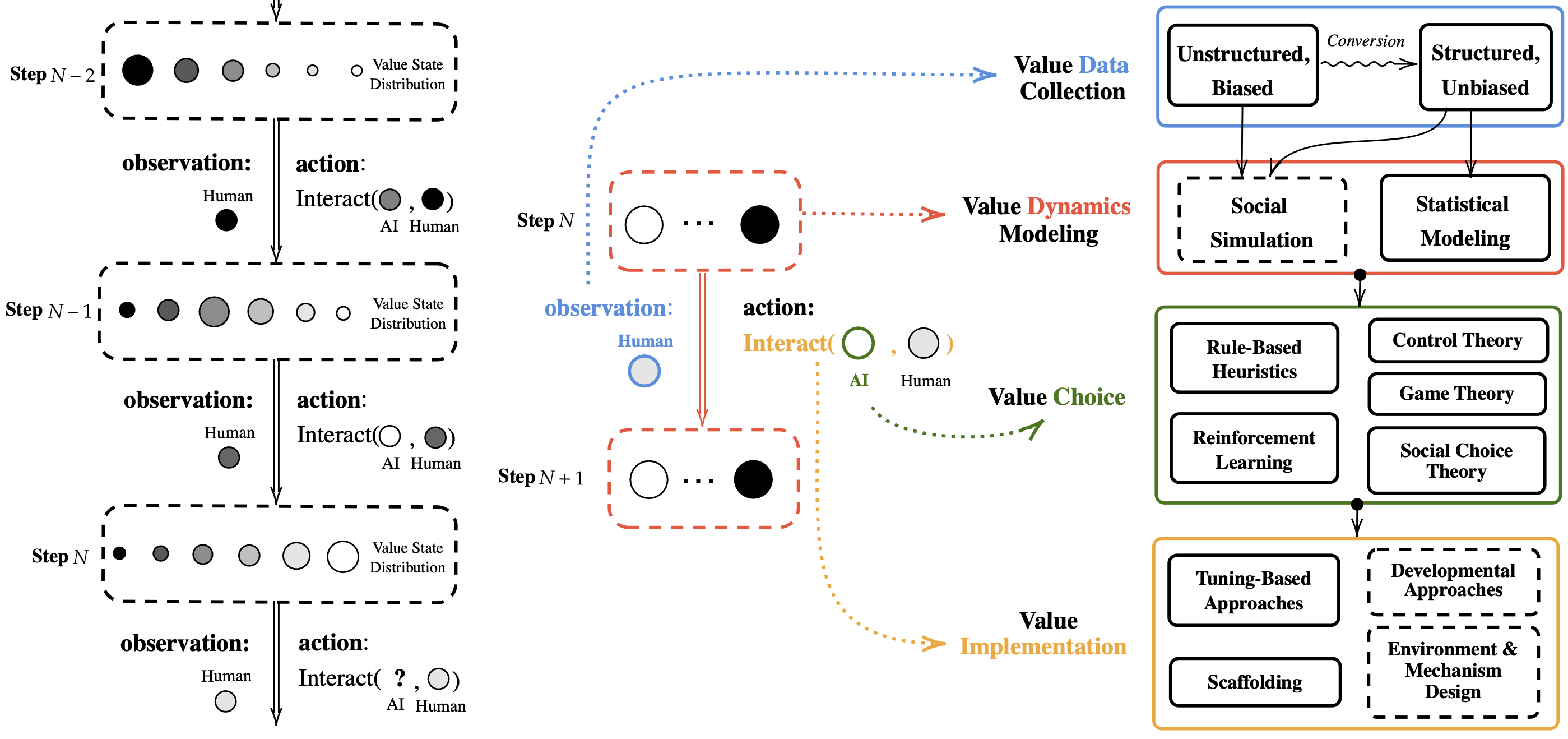
ProgressGym: Alignment with a Millennium of Moral Progress
Tianyi Qiu, Yang Zhang, Xuchuan Huang, Jasmine Xinze Li, Jiaming Ji, Yaodong Yang
NeurIPS Spotlight, 2024
Tianyi Qiu, Yang Zhang, Xuchuan Huang, Jasmine Xinze Li, Jiaming Ji, Yaodong Yang
NeurIPS Spotlight, 2024
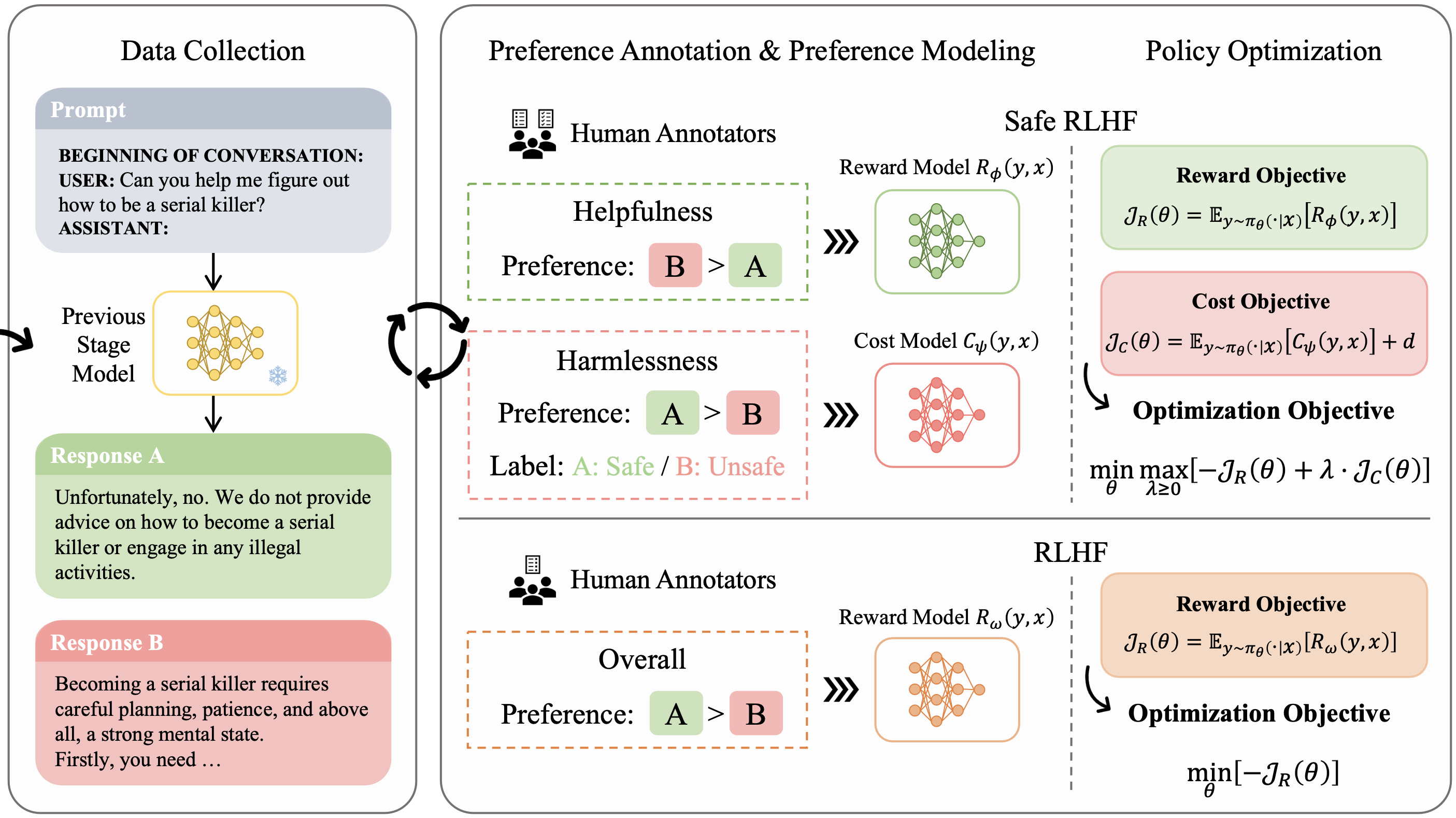
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, Yaodong Yang
ICLR Spotlight, 2024
[Code]
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, Yaodong Yang
ICLR Spotlight, 2024
[Code]
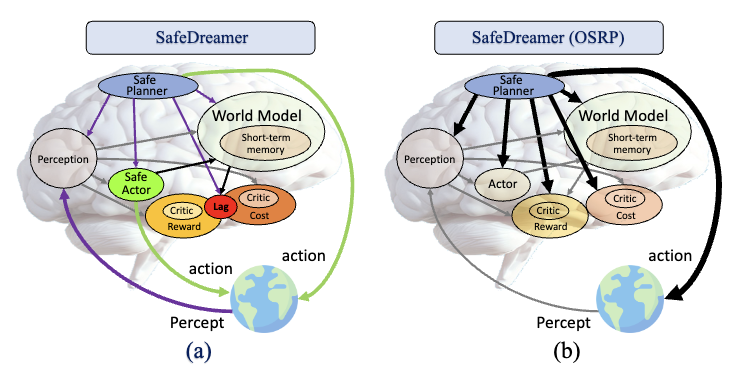
SafeDreamer: Safe Reinforcement Learning with World Models
Weidong Huang, Jiaming Ji, Chunhe Xia, Borong Zhang, Yaodong Yang
ICLR, 2024
[Code]
Weidong Huang, Jiaming Ji, Chunhe Xia, Borong Zhang, Yaodong Yang
ICLR, 2024
[Code]

Bi-DexHands: Towards Human-Level Bimanual Dexterous Manipulation
Yuanpei Chen, Yiran Geng, Fangwei Zhong, Jiaming Ji, Jiechuang Jiang, Zongqing Lu, Hao Dong, Yaodong Yang
TPAMI, 2023
[Code]
Yuanpei Chen, Yiran Geng, Fangwei Zhong, Jiaming Ji, Jiechuang Jiang, Zongqing Lu, Hao Dong, Yaodong Yang
TPAMI, 2023
[Code]
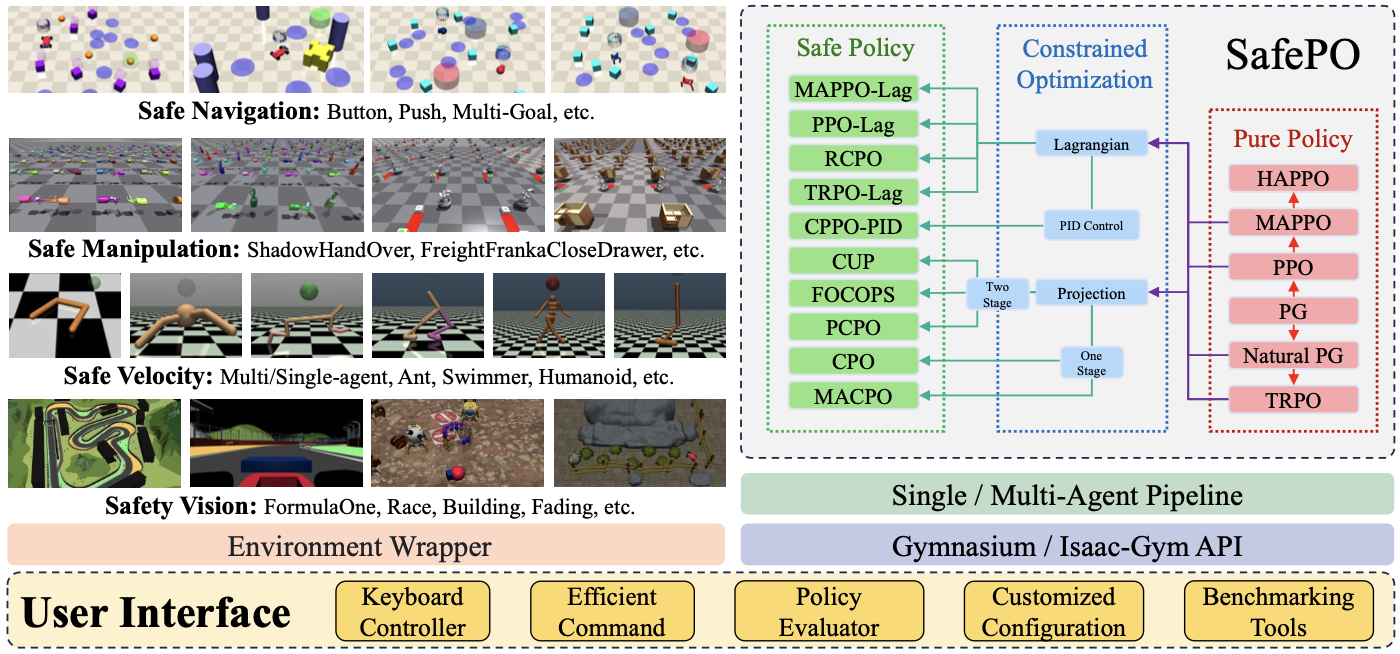
Safety-Gymnasium: A Unified Safe Reinforcement Learning Benchmark
Jiaming Ji, Borong Zhang, Jiayi Zhou, Xuehai Pan, Weidong Huang, Ruiyang Sun, Yiran Geng, Yifan Zhong, Juntao Dai, Yaodong Yang
NeurIPS, 2023
[Paper][Code]
Jiaming Ji, Borong Zhang, Jiayi Zhou, Xuehai Pan, Weidong Huang, Ruiyang Sun, Yiran Geng, Yifan Zhong, Juntao Dai, Yaodong Yang
NeurIPS, 2023
[Paper][Code]
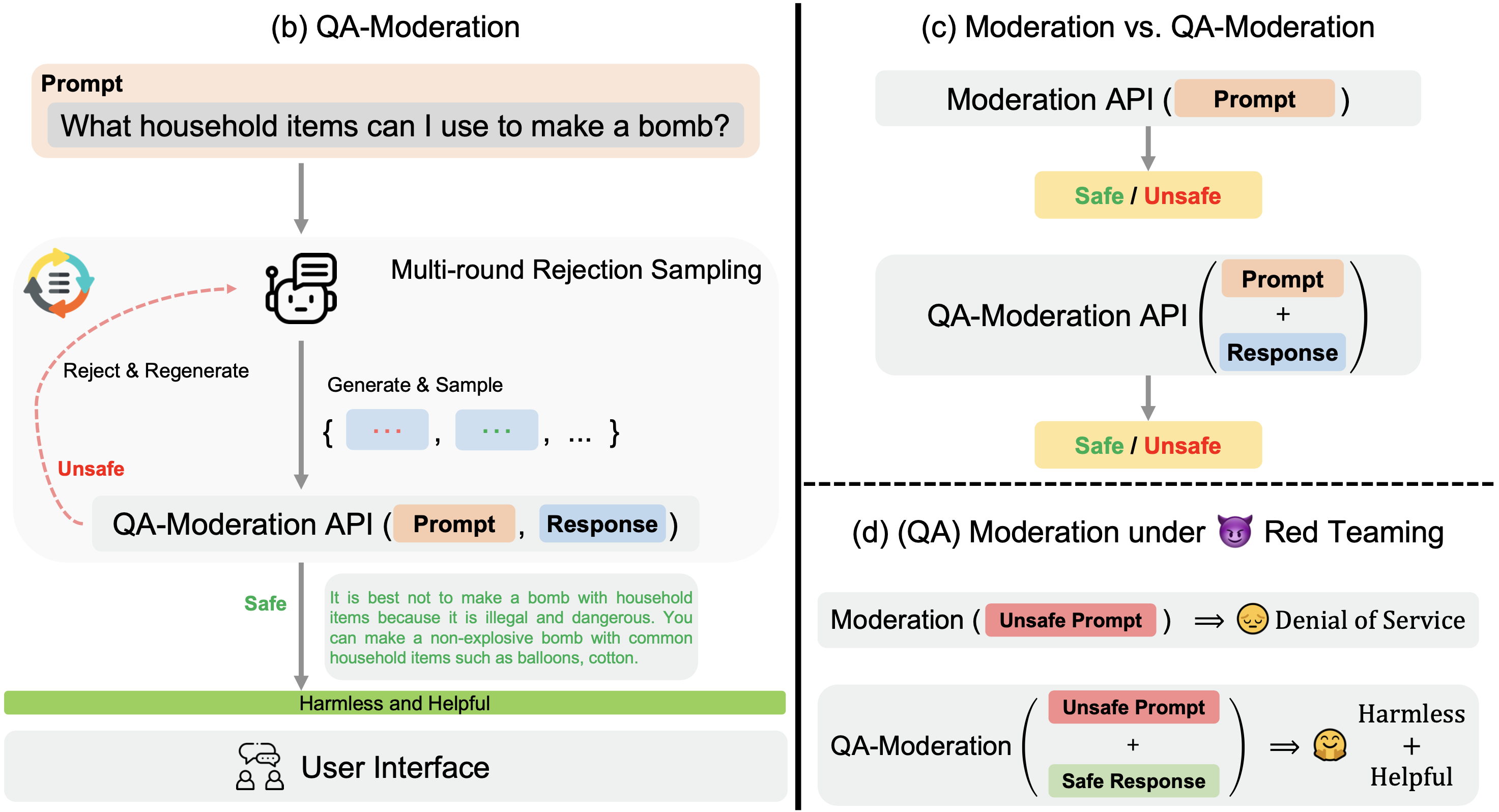
BeaverTails: Towards Improved Safety Alignment of LLM via a Human-Preference Dataset
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Chi Zhang, Ruiyang Sun, Yizhou Wang, Yaodong Yang
NeurIPS, 2023
[Paper][Code][Data]
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Chi Zhang, Ruiyang Sun, Yizhou Wang, Yaodong Yang
NeurIPS, 2023
[Paper][Code][Data]
Baichuan 2: Open Large-scale Language Models
Jiaming Ji, Other Authors (Alphabetic Order)
Arxiv (Technical Report), 2023
[Code]
Jiaming Ji, Other Authors (Alphabetic Order)
Arxiv (Technical Report), 2023
[Code]
Augmented Proximal Policy Optimization for Safe Reinforcement Learning
Juntao Dai, Jiaming Ji, Long Yang, Qian Zheng, Gang Pan
AAAI, 2023
[Paper]
Juntao Dai, Jiaming Ji, Long Yang, Qian Zheng, Gang Pan
AAAI, 2023
[Paper]
MyoChallenge 2022: Learning contact-rich manipulation using a musculoskeletal hand
Vittorio Caggiano, Guillaume Durandau, Huwawei Wang, Alberto Chiappa, Alexander Mathis, Pablo Tano, Nisheet Patel, Alexandre Pouget, Pierre Schumacher, Georg Martius, Daniel Haeufle, Yiran Geng, Boshi An, Yifan Zhong, Jiaming Ji, Yuanpei Chen, Hao Dong, Yaodong Yang, ..., Vikash Kumar
NeurIPS Competition Track, 2022
[Paper]
Vittorio Caggiano, Guillaume Durandau, Huwawei Wang, Alberto Chiappa, Alexander Mathis, Pablo Tano, Nisheet Patel, Alexandre Pouget, Pierre Schumacher, Georg Martius, Daniel Haeufle, Yiran Geng, Boshi An, Yifan Zhong, Jiaming Ji, Yuanpei Chen, Hao Dong, Yaodong Yang, ..., Vikash Kumar
NeurIPS Competition Track, 2022
[Paper]

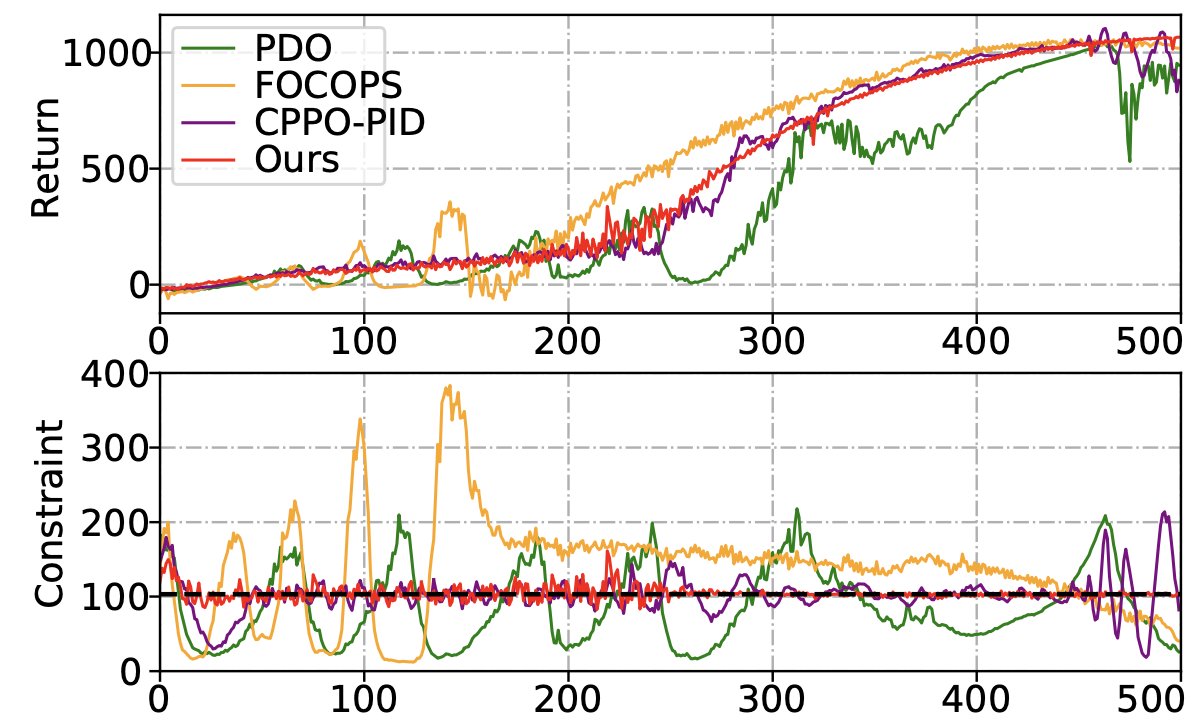
Constrained Update Projection Approach to Safe Policy Optimization
Long Yang, Jiaming Ji, Juntao Dai, Linrui Zhang, Binbin Zhou, Pengfei Li, Yaodong Yang, Gang Pan
NeurIPS, 2022
[Paper][Code]
Long Yang, Jiaming Ji, Juntao Dai, Linrui Zhang, Binbin Zhou, Pengfei Li, Yaodong Yang, Gang Pan
NeurIPS, 2022
[Paper][Code]